심층 학습 가이드
Vercel 빌드 없이 DB만으로 포스팅 갱신하는 방법
AI 콘텐츠 자동화 무배포 포스팅 루프 — Turso 업로드와 revalidate로 공개 화면을 갱신하는 VIBE 코딩 운영법
- 핵심 주제
- DB Runtime Publishing
- 예상 시간
- 19분
- 업데이트
- 2026.04.30
- 키워드
- Vercel 빌드 없이 포스팅 · DB 업로드 revalidate · Turso 포스팅
콘텐츠 한 줄을 고치려고 Vercel 빌드를 처음부터 다시 돌릴 필요는 없습니다. VIBE 코딩에서 무배포 포스팅은 편의 기능이 아니라 운영 안전장치입니다. AI가 글을 만들고 사람이 승인하면, 코드를 배포하지 않고 데이터베이스에만 반영한 뒤 revalidate로 공개 화면을 갱신합니다. 이 흐름을 만들면 콘텐츠 생산 속도는 올라가고, 불필요한 Production 배포와 빌드 충돌은 줄어듭니다.
핵심 명제는 단순합니다. "AI가 글을 썼다"와 "사이트에 안전하게 공개됐다"를 분리해야 한다는 것입니다. 전자는 초안 작성이고, 후자는 운영입니다. 이 둘을 분리하지 않으면 AI 자동화가 빨라질수록 사이트 품질이 망가질 위험도 같이 커집니다.
이 글은 단순한 개념 설명이 아니라 실제로 굴러가는 운영 매뉴얼입니다. 실제 API 라우트 코드, 명령어, 자주 빠지는 함정과 그 해결법, 되돌리기 절차, AI에게 일을 맡기는 프롬프트까지 한 흐름으로 정리합니다. 처음 읽는 분은 위에서 아래로 읽고, 운영자라면 필요한 섹션만 골라 보면 됩니다.
한눈에 보는 전체 흐름
무배포 포스팅 루프는 세 개의 레인(lane)으로 이해하면 쉽습니다.
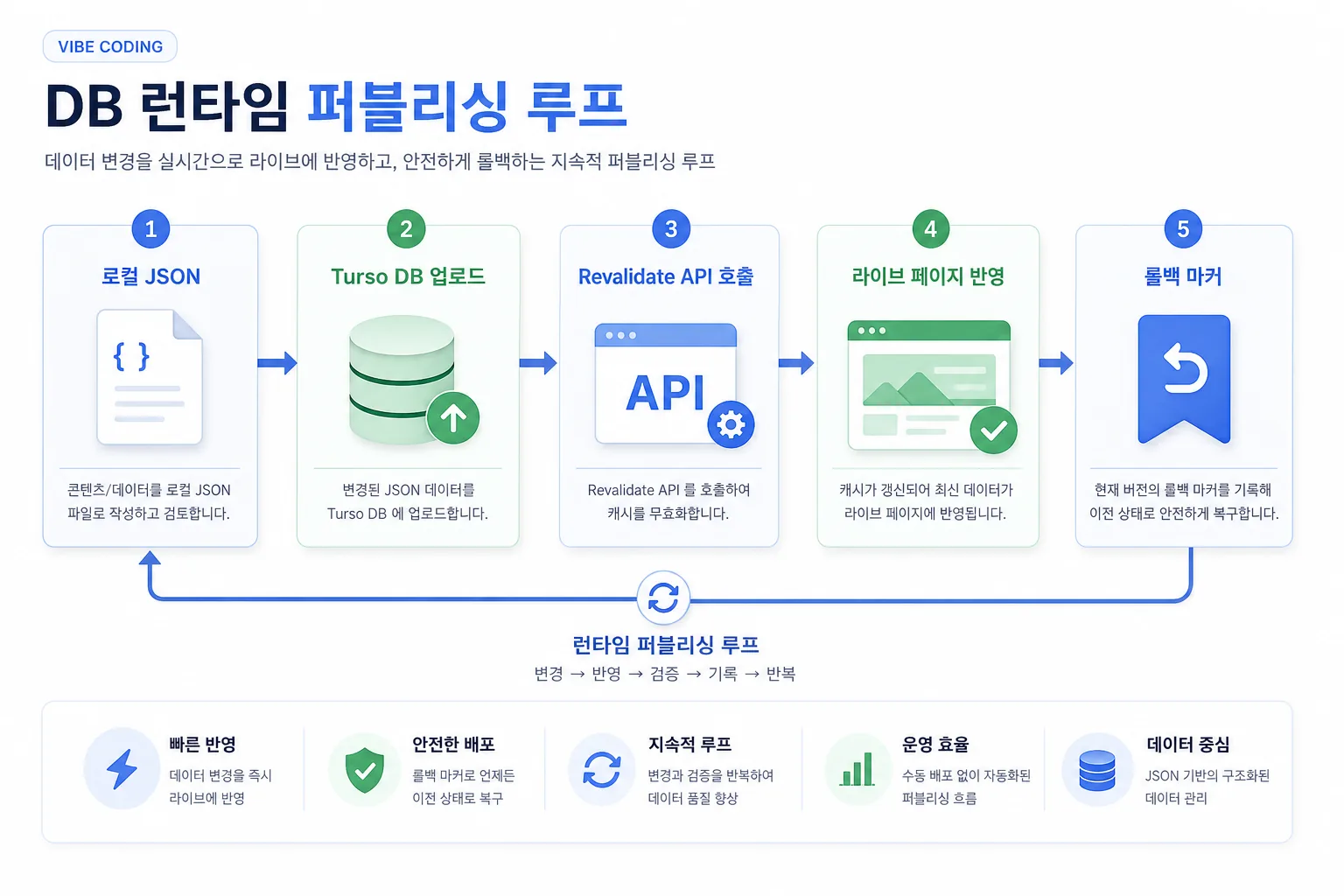
[로컬 원천] [DB 런타임] [공개 화면]
local JSON ─────▶ Turso row ─────▶ Next.js page
▲ │ │
│ ▼ ▼
[ Git 보관 ] [ revalidate API ] [ live smoke ]
되돌리기 기준 캐시 무효화 공개 확인왼쪽은 사람이 다루는 영역, 가운데는 시스템이 다루는 영역, 오른쪽은 독자가 보는 영역입니다. 무배포 포스팅의 비밀은 가운데 레인만 움직이고 코드 레인은 건드리지 않는 것입니다. 코드 배포는 빌드, 라우팅, 컴포넌트, 의존성을 함께 흔들지만, 데이터 갱신은 렌더러가 이미 안정적이라는 전제에서 글 데이터만 바꿉니다.
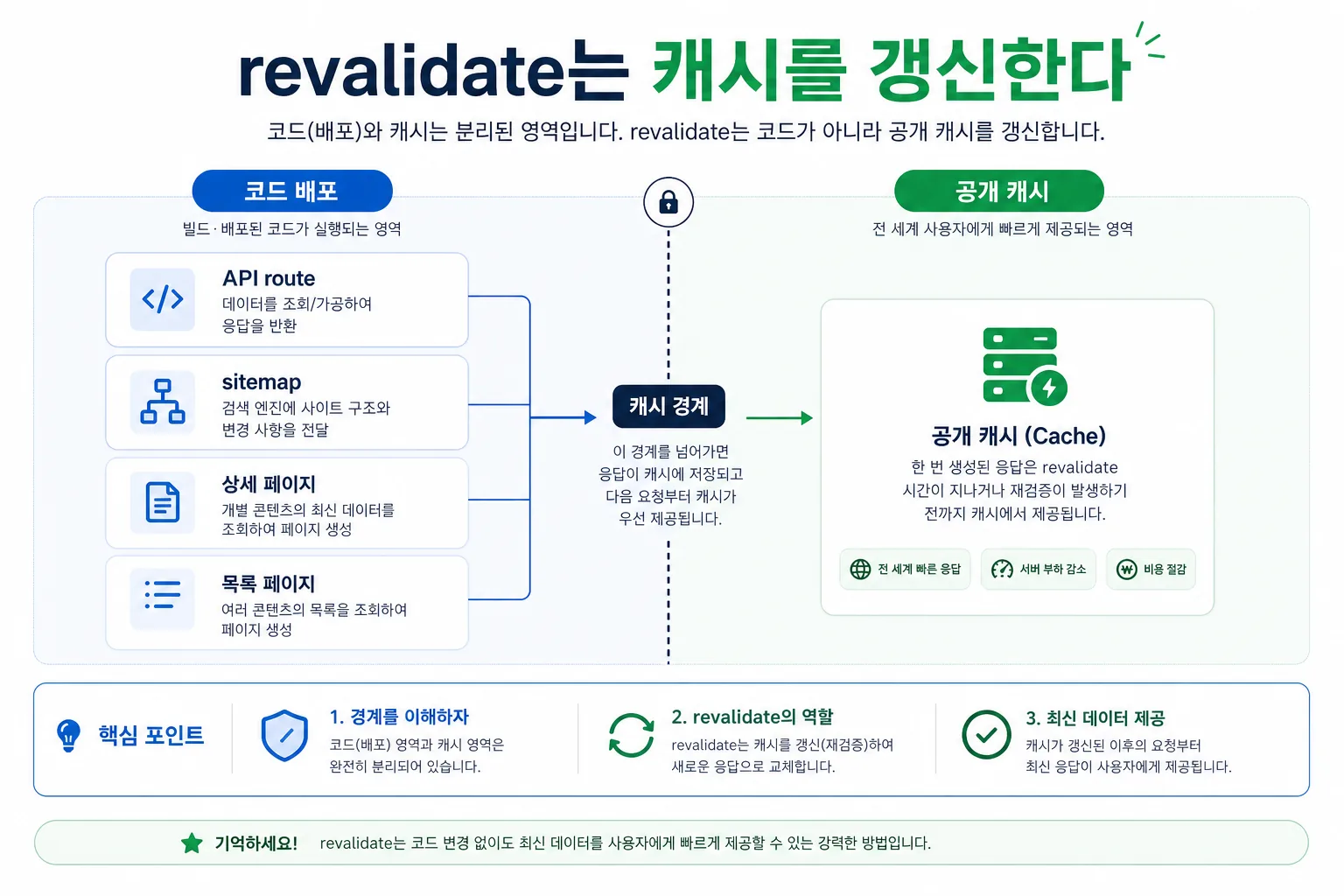
왜 빌드 없이 가능한가 — Next.js ISR과 revalidate의 원리
이 운영법이 가능한 이유는 Next.js의 ISR(Incremental Static Regeneration) 덕분입니다. 페이지를 정적으로 캐시해 두되, 필요할 때만 다시 생성하는 구조입니다.

이미지 설명: 콘텐츠 원본, 운영 DB, 공개 캐시가 어떻게 분리되는지 한눈에 보여 주는 흐름도입니다. 핵심 함수는 두 가지입니다.
| 함수 | 용도 | 사용 시점 |
|---|---|---|
revalidatePath('/blog/[slug]') | 특정 경로의 캐시를 무효화 | 글 1개를 새로 공개하거나 수정할 때 |
revalidateTag('posts') | 특정 태그가 붙은 모든 캐시를 무효화 | 여러 페이지가 같은 데이터를 공유할 때 |
revalidatePath는 정밀 갱신, revalidateTag는 광역 갱신입니다. 무배포 포스팅에서는 보통 둘을 같이 씁니다. 상세 페이지는 revalidatePath로 정확히 찍고, 목록·홈·sitemap은 revalidateTag로 일괄 갱신하는 식입니다.
중요한 차이: revalidate는 빌드가 아닙니다. 빌드는 코드를 다시 컴파일해 새 번들을 만들지만, revalidate는 이미 배포된 코드 위에서 "다음 요청 때 데이터를 다시 가져와라"는 신호만 보냅니다. 그래서 1~2초 안에 끝나고, 빌드 큐도 차지하지 않습니다.
이 루프를 굴리는 3가지 시점
무배포 포스팅 루프는 한 번 만들어 두면 끝나는 자동화가 아닙니다. 작업 시작 전, 실행 중, 완료 후 세 시점에 각각 다른 확인이 필요합니다.
적용 전 확인. 작업을 시작하기 전에 바꿀 파일, 기대 결과, 검증 명령, 되돌리기 방법을 먼저 정합니다. AI에게 넓은 목표만 주면 빠르게 결과를 만들 수는 있지만, 사람이 검토할 수 없는 큰 변경으로 번질 가능성이 높습니다.
실행 중 관찰. 중간 결과는 코드 모양이 아니라 동작 증거로 판단합니다. 테스트가 통과하는지, 공개 화면 marker가 보이는지, 콘솔 오류가 없는지, 내부 문구나 민감한 값이 노출되지 않는지를 순서대로 확인합니다.
완료 후 기록. 마지막에는 무엇을 바꿨고 어떤 검증을 했으며 남은 위험이 무엇인지 짧게 남깁니다. 이 기록은 다음 AI 세션이나 팀원이 같은 맥락을 되찾는 데 필요한 최소한의 운영 기억입니다.
언제 이 루프를 쓰고, 언제 쓰면 안 되는가
무배포 포스팅이 적합한 작업과 그렇지 않은 작업을 미리 구분해야 합니다. AI에게 작업을 맡길 때 이 경계를 먼저 알려주지 않으면, 에이전트가 콘텐츠 작업 중 코드까지 건드릴 수 있습니다.
| 작업 | 적합 여부 | 이유 |
|---|---|---|
| 글 제목·본문·태그·발행일 수정 | ✅ DB 루프 | 데이터 변경, 렌더러는 그대로 |
| AI 뉴스 오탈자 수정·출처 보강 | ✅ DB 루프 | 본문 텍스트만 변경 |
| Hermes 팁 체크리스트 항목 추가 | ✅ DB 루프 | 본문 구조 안에서 해결 가능 |
| FAQ 항목 추가·수정 | ✅ DB 루프 | JSON 필드 변경 |
| 새 Markdown 문법 지원 추가 | ❌ 코드 배포 | 렌더러 변경 필요 |
| 상세 페이지 메타데이터 생성 방식 변경 | ❌ 코드 배포 | generateMetadata 함수 수정 |
| Q&A 상태 라벨 변경 | ❌ 코드 배포 | 컴포넌트와 상수 수정 |
| 카드 디자인·레이아웃 변경 | ❌ 코드 배포 | UI 컴포넌트 수정 |
| 새 카테고리 추가 | ⚠️ 혼합 | 라우팅·메뉴는 코드, 글은 데이터 |
| sitemap 구조 변경 | ❌ 코드 배포 | sitemap.ts 수정 |
같은 "글 수정"처럼 보여도 실제 변경 경로가 다른 경우는 흔합니다. 작업 시작 전에 이 구분을 먼저 하면 AI가 엉뚱한 파일을 건드리는 사고를 막을 수 있습니다.
전체 루프 한눈에 보기
무배포 포스팅 루프는 여섯 단계로 구성됩니다. 자동화해도 되지만 어느 한 단계도 생략하면 안 됩니다.
이미지 설명: revalidate가 바꾸는 것은 코드가 아니라 캐시와 공개 화면이라는 점을 구분합니다. | 단계 | 작업 | 확인할 것 | 실패 시 행동 | | --- | --- | --- | --- | | 1 | 로컬 JSON 작성 | slug, category, title, content, publishedAt | 초안으로 되돌리고 보강 | | 2 | validation 실행 | 필수 필드와 위험 HTML 없음 | 업로드 금지 | | 3 | 품질 검토 | 얕은 요약, 중복, 출처 부족 없음 | 본문 보강 후 재검토 | | 4 | DB 업로드 | 대상 post id와 slug가 정확히 반영됨 | 로컬 원천과 DB 상태 비교 | | 5 | revalidate | 목록·상세·홈·sitemap 갱신 | revalidate 재실행 | | 6 | live smoke | 200 응답, 제목 마커, 콘솔 오류 없음 | revalidate 재실행 또는 롤백 |
특히 3번 품질 검토와 6번 live smoke가 빠지면 "형식상 성공했지만 독자에게는 나쁜 글"이 공개됩니다. 명령 성공 로그는 공개 성공과 다릅니다. 이 루프의 완료 기준은 명령 성공이 아니라 라이브 화면에서 새 제목·본문 marker·공유 설명까지 확인되는 순간입니다.
실제 구현 — API 라우트와 명령어
이론만으로는 굴러가지 않습니다. 실제로 어떻게 코드를 짜는지 보여 드립니다. Next.js App Router 기준 최소 예시입니다.
revalidate API 라우트
// app/api/revalidate/route.ts
import { revalidatePath, revalidateTag } from 'next/cache';
import { NextRequest, NextResponse } from 'next/server';
export async function POST(req: NextRequest) {
const authValue = req.headers.get('x-revalidate-auth');
if (authValue !== getRevalidateAuthValue()) {
return NextResponse.json({ ok: false, error: 'unauthorized' }, { status: 401 });
}
const { slug, category } = await req.json();
if (!slug || !category) {
return NextResponse.json({ ok: false, error: 'missing slug or category' }, { status: 400 });
}
// 정밀 갱신: 상세 페이지
revalidatePath(`/${category}/${slug}`);
// 광역 갱신: 목록·홈·sitemap이 공유하는 태그
revalidateTag(`posts:${category}`);
revalidateTag('posts:home');
revalidatePath('/sitemap.xml');
return NextResponse.json({ ok: true, revalidated: { slug, category } });
}핵심 포인트 세 가지. x-revalidate-auth 헤더로 인증, revalidatePath로 정밀 갱신, revalidateTag로 광역 갱신을 같이 호출합니다. 인증이 빠지면 누구나 호출해 캐시를 마음대로 깰 수 있으니 절대 빠뜨리면 안 됩니다.
DB 업로드 + revalidate 한 번에 호출
// scripts/publish.ts
import { db } from '@/lib/turso';
import fs from 'node:fs/promises';
async function publish(jsonPath: string) {
const raw = await fs.readFile(jsonPath, 'utf-8');
const post = JSON.parse(raw);
// 1. 스키마 검증 (zod 등으로 별도 구현)
validatePost(post);
// 2. DB upsert
await db.execute({
sql: `INSERT INTO posts (id, slug, category, title, content, published_at, status)
VALUES (?, ?, ?, ?, ?, ?, 'published')
ON CONFLICT(id) DO UPDATE SET
slug = excluded.slug,
title = excluded.title,
content = excluded.content,
published_at = excluded.published_at,
status = 'published',
updated_at = CURRENT_TIMESTAMP`,
args: [post.id, post.slug, post.category, post.title, post.content, post.publishedAt],
});
// 3. revalidate
const res = await fetch(`${getSiteUrl()}/api/revalidate`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-revalidate-auth': getRevalidateAuthValue()!,
},
body: JSON.stringify({ slug: post.slug, category: post.category }),
});
if (!res.ok) throw new Error(`revalidate failed: ${res.status}`);
console.log(`✅ published: /${post.category}/${post.slug}`);
}
publish(process.argv[2]);실행은 한 줄입니다.
npx tsx scripts/publish.ts content/vibe/db-revalidate-publishing-loop.jsonlive smoke 자동화
공개 직후 정말로 새 글이 보이는지 자동 확인합니다.
# scripts/smoke.sh
#!/bin/bash
SLUG=$1
CATEGORY=$2
MARKER=$3 # 예: 글 제목의 한 단어
DETAIL_URL="https://example.com/${CATEGORY}/${SLUG}"
LIST_URL="https://example.com/${CATEGORY}"
# 1. 상세 페이지 200 + 마커 확인
curl -sf "$DETAIL_URL" | grep -q "$MARKER" \
&& echo "✅ detail OK" || { echo "❌ detail FAIL"; exit 1; }
# 2. 목록 페이지에 카드 노출 확인
curl -sf "$LIST_URL" | grep -q "$SLUG" \
&& echo "✅ list OK" || { echo "❌ list FAIL"; exit 1; }
echo "🎉 smoke passed"명령 성공이 곧 공개 성공이 아니라는 점을 기억하세요. smoke 테스트가 통과해야 진짜 공개입니다.
자주 빠지는 함정 6가지와 해결법
실무에서 한 번씩은 모두 겪는 실수들입니다.
함정 1. JSON validation만 통과하면 좋은 글이라고 착각
스키마는 맞아도 본문이 얕으면 독자는 바로 이탈합니다. 검증은 형식이고, 품질은 사람이 한 번 더 봐야 합니다. 해결법: validation 통과 후 "읽고 가치를 얻을 한 문장"을 본인이 직접 말로 정리해 보고, 그게 안 나오면 본문을 보강합니다.
함정 2. DB 업로드 성공 = 공개 성공으로 착각
캐시가 갱신되지 않으면 라이브 화면은 예전 상태로 남아 있습니다. 해결법: 업로드 스크립트에 반드시 revalidate 호출과 live smoke를 묶어 한 흐름으로 실행하고, smoke 실패 시 비공개로 자동 롤백합니다.
함정 3. 상세만 확인하고 목록을 안 보는 것
상세는 정상이어도 목록 카드가 안 보이거나 예전 설명을 보여주면 독자는 새 글을 발견하지 못합니다. 해결법: revalidate 대상에 상세·목록·홈·sitemap을 모두 포함하고, smoke 스크립트가 목록까지 확인하게 합니다.
함정 4. 내부 문구를 그대로 공개
"내부 메모", "임시 작성", "테스트용" 같은 표현은 방문자에게 내부 관리 화면을 보는 느낌을 줍니다. 해결법: 발행 직전 본문에서 금지어 목록(내부, 임시, 테스트, TODO, FIXME, XXX)을 grep으로 한 번 훑고, 걸리면 발행을 차단합니다.
if grep -E "내부|임시|TODO|FIXME|XXX" content/vibe/$SLUG.json; then
echo "❌ forbidden words found"; exit 1
fi함정 5. revalidate가 됐는데도 화면이 안 바뀜
CDN 캐시(Cloudflare 등) 때문일 수 있습니다. Next.js 캐시는 풀렸어도 그 앞단 CDN이 예전 응답을 들고 있으면 독자는 옛 화면을 봅니다. 해결법: CDN에서 해당 경로를 purge하거나, Cache-Control 헤더를 짧게 설정하거나, 캐시 키에 revalidatedAt 타임스탬프를 포함시킵니다.
함정 6. AI가 글 수정하다가 코드까지 건드림
AI에게 "이 글 좀 고쳐줘"라고만 말하면, 본문에 표가 깨져 있을 때 renderer 컴포넌트까지 수정해 PR을 만들어 버립니다. 해결법: 프롬프트에 "코드 파일은 건드리지 않는다. 의심되면 보류로 보고한다"를 명시하고, 작업 폴더를 content/ 디렉터리로 제한합니다.
왜 코드 배포와 분리해야 하나 — 3가지 운영 이익
콘텐츠 변경마다 Production 배포를 만들면 작은 문구 수정도 전체 앱 릴리스가 됩니다. 두 흐름을 분리하면 얻는 이익이 큽니다.
첫째, 빌드 시간만큼 공개 속도가 빨라집니다. 일반적인 Next.js 사이트의 Vercel 빌드는 30초~3분이 걸립니다. revalidate는 1~2초입니다. 글 10개를 하루에 올린다면 분 단위가 시간 단위로 절약됩니다.
둘째, "글 고쳤는데 앱이 회귀"하는 사고가 사라집니다. 코드 배포는 의존성 업데이트, 빌드 캐시 문제, 환경변수 변경, 라우팅 충돌을 같이 가져옵니다. 데이터 갱신은 이런 변수가 없습니다.
셋째, 사고가 났을 때 원인이 즉시 구분됩니다. 공개 후 문제가 생겼을 때 "마지막에 한 작업이 데이터인가, 코드인가"가 명확하면 디버깅이 5분으로 끝납니다. 두 흐름이 섞이면 한 시간 걸립니다.
AI 자동화를 도입할수록 이 분리가 더 중요해집니다. AI가 코드까지 같이 건드리는 순간 작은 콘텐츠 수정이 큰 회귀로 번질 수 있기 때문입니다.
AI에게 일을 맡기는 법 — 좋은 프롬프트와 나쁜 프롬프트
같은 작업이라도 프롬프트에 따라 결과가 완전히 달라집니다.
나쁜 예
AI 뉴스 1개 새로 올려줘.
범위가 넓고 완료 조건이 없어, AI가 코드까지 건드리거나 얕은 본문을 만들 수 있습니다.
좋은 예
이 글은 데이터만 변경한다. 다음 순서로 진행한다.
1.content/ai-news/폴더에 새 JSON을 작성한다. 기존 글 2개 구조를 먼저 읽고 같은 스키마를 따른다.
2. validation을 실행한다. 실패하면 멈춘다.
3. 본문이 독자에게 1개 이상의 실행 가치(따라 할 행동, 알아야 할 사실, 피해야 할 함정)를 주는지 자체 점검한다.
4.npx tsx scripts/publish.ts로 DB 업로드와 revalidate를 수행한다.
5.bash scripts/smoke.sh로 상세와 목록 양쪽의 마커를 확인한다.
6. 코드 파일(app/,components/,lib/)은 건드리지 않는다. 의심되면 보류로 보고한다.
7. 완료 후 변경 파일, 검증 결과, 남은 리스크를 3줄로 보고한다.
이 프롬프트는 일곱 가지를 한 번에 전달합니다. 작업의 성격, 실행 경로, 검증 명령, 자체 품질 기준, 권한 경계, 보고 형식, 중단 조건. AI에게 작성자가 아니라 운영자로 행동하게 만드는 지시입니다.
VIBE 코딩의 핵심은 AI가 빨리 쓰게 하는 것이 아니라, AI가 안전하게 끝내게 하는 것입니다.
되돌리기 절차 — 공개 후 문제가 발견됐을 때
무배포 포스팅의 가장 큰 약점은 Git revert로 되돌릴 수 없다는 것입니다. DB만 바꿨기 때문에 코드 히스토리에 흔적이 없습니다. 그래서 되돌리기 방법을 작업 시작 전에 미리 정해 두어야 합니다.

이미지 설명: 업로드 후 목록·상세·API에서 marker를 확인하고 문제가 있으면 이전 JSON으로 되돌리는 절차입니다. 상황별 되돌리기 방법은 다음과 같습니다.
| 상황 | 방법 | 소요 시간 |
|---|---|---|
| 글 전체에 문제 (오정보·유출·민감 표현) | status를 draft로 토글 + revalidate | 30초 |
| 일부 문구만 문제 | 해당 필드만 UPDATE + revalidate | 1분 |
| 이전 버전으로 완전 복구 | 로컬 JSON 이전 버전 재업로드 | 2분 |
| 글 자체가 잘못 발행됨 | DB row 삭제 + revalidate + sitemap 갱신 | 2분 |
가장 빠른 응급 조치는 상태 토글입니다.
UPDATE posts SET status = 'draft', published_at = NULL WHERE slug = '문제글_slug';그 다음 revalidate를 호출하면 공개 화면에서 사라집니다. 글은 DB에 그대로 남아 있으니 조사 후 다시 살릴 수 있습니다.
전체 복구는 로컬 JSON 원천이 있어야 가능합니다. 이래서 로컬 JSON을 원천으로 유지하는 것이 중요합니다. DB만 보고 작업하면 되돌릴 기준점이 사라집니다. 가능하면 content/ 폴더를 Git으로 관리해 각 글의 변경 이력을 남기세요. 코드는 배포하지 않더라도 콘텐츠는 버전 관리되어야 합니다.
어떤 방법을 쓰든 되돌리기 후에도 반드시 live smoke로 공개 화면을 한 번 더 확인해야 합니다. 캐시 때문에 되돌렸는데도 예전 화면이 남아 있는 경우가 있기 때문입니다.
운영 시나리오 3가지
실제로 어떻게 굴러가는지 시나리오로 보여 드립니다.
시나리오 A — 오탈자 긴급 수정
공개된 글에서 회사명이 잘못 적혀 있는 걸 독자가 제보했습니다.
- 로컬 JSON에서 해당 단어 수정 (10초)
npx tsx scripts/publish.ts content/news/post-123.json(2초)bash scripts/smoke.sh post-123 news "올바른 회사명"(3초)- 독자에게 "수정 완료" 답변
총 소요: 약 30초. Vercel 빌드를 거치면 같은 작업이 2~3분 걸립니다.
시나리오 B — AI가 야간에 만든 글 발행
새벽 3시에 Hermes Agent가 AI 뉴스 초안 5개를 만들어 content/ai-news/drafts/에 떨궈 놓았습니다.
- 아침에 사람이 5개를 검토 (15분)
- 3개는 합격, 2개는 본문 보강 후 합격 (10분)
- 5개를 일괄 publish 스크립트로 발행 (1분)
- 사이트맵과 RSS 갱신 자동 (포함)
- SNS 채널에 새 글 알림 (자동 훅)
핵심: AI는 초안까지, 사람은 발행 결정까지. 둘 사이에 명확한 게이트가 있어야 자동화가 위험해지지 않습니다.
시나리오 C — 발행 후 사실 오류 발견
공개 1시간 뒤 통계 수치가 틀렸다는 제보를 받았습니다.
- 즉시 status를
draft로 토글 + revalidate (30초) - 글이 사이트에서 사라진 것을 smoke로 확인 (10초)
- 정확한 수치 조사 (10분)
- 로컬 JSON 수정 후 재발행 (1분)
- "수정 안내" 한 줄을 글 끝에 추가
핵심: 공개 → 사라짐 → 수정 → 재공개가 모두 코드 배포 없이 가능합니다.
모니터링과 알림 — 사고를 빨리 알아채는 법
무배포 포스팅이 빠른 만큼 사고도 빨리 퍼집니다. 다음 세 가지 알림은 미리 붙여 두세요.
publish 알림. 새 글이 발행될 때마다 Slack/Telegram 채널에 "제목 + URL + 작성자(사람/AI)"를 자동 전송. AI가 만든 글은 별도 채널로 분리하면 사후 검토가 쉽습니다.
smoke 실패 알림. smoke 테스트가 실패하면 즉시 알림. 이 경우 자동으로 status를 draft로 되돌리는 훅을 붙여도 좋습니다.
일일 다이제스트. 매일 아침 "어제 발행된 글, 평균 발행 시간, 실패 건수, AI 작성 비율"을 요약. 운영 패턴이 이상해지면 일찍 알아챌 수 있습니다.
보안 — 절대 빠뜨리면 안 되는 4가지
무배포 포스팅 API는 잘못 노출되면 사이트 콘텐츠가 통째로 위험해집니다.
첫째, revalidate API는 반드시 시크릿으로 보호합니다. x-revalidate-auth 헤더 검증 없이 열어 두면 누구나 캐시를 깰 수 있고, 최악의 경우 DoS 벡터가 됩니다.
둘째, publish 스크립트는 사람 인증 뒤에만 실행합니다. CI에서 자동 실행하더라도 사람 승인 단계(GitHub Actions의 environment approval 등)를 거치게 합니다.
셋째, DB write 권한 토큰과 read 권한 토큰을 분리합니다. Turso의 경우 토큰별 권한 설정이 가능하니, 공개 페이지 렌더링용 토큰은 read-only로 만듭니다.
넷째, AI 에이전트의 작업 폴더를 content/로 제한합니다. AI가 실수로 app/ 폴더의 라우트나 환경 변수 파일 파일을 건드리지 못하게 합니다.
최종 체크리스트
작업을 시작하기 전과 공개 직후에 한 번씩 훑어 보세요.
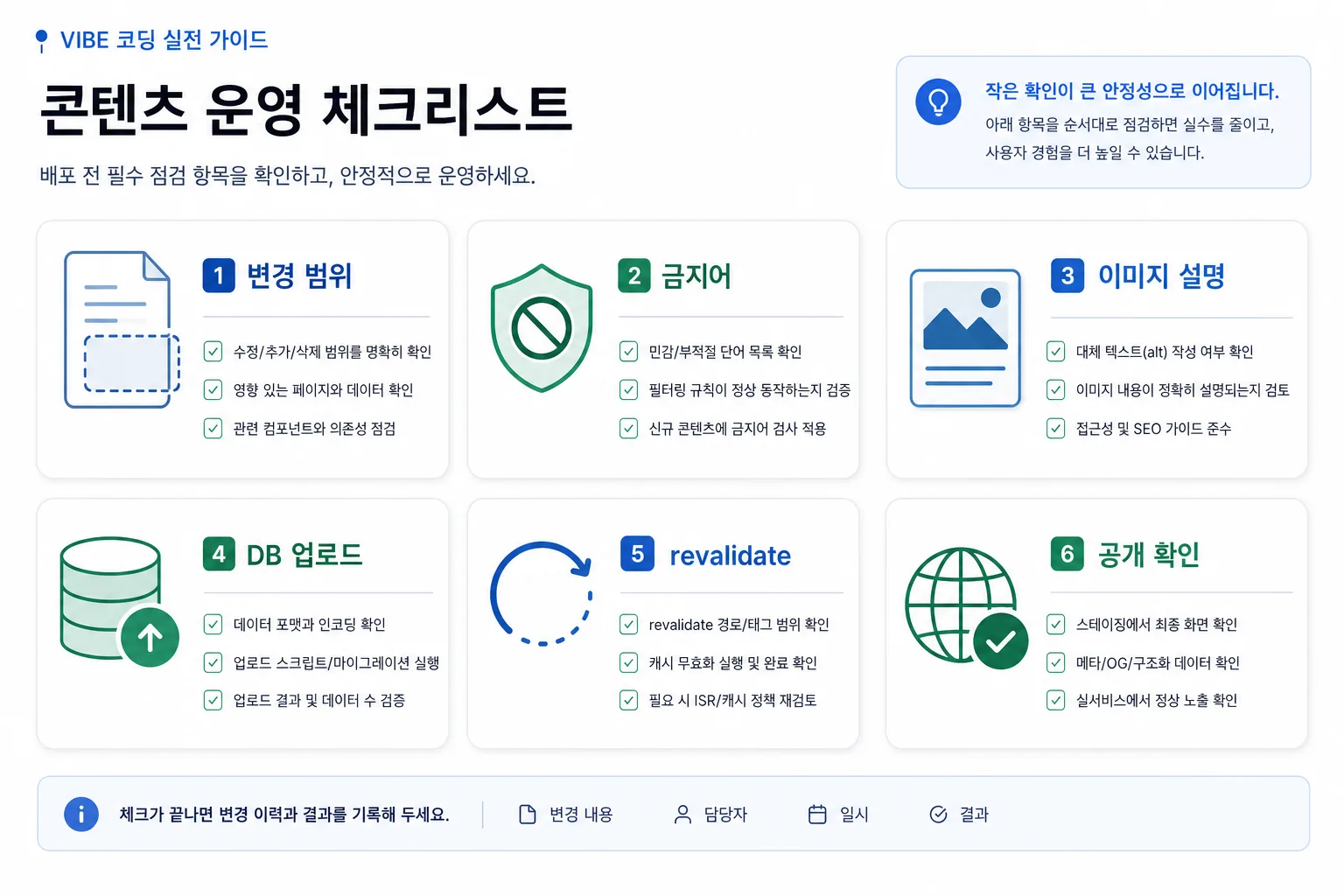
이미지 설명: AI가 글을 만들고 사람이 승인할 때 빠뜨리면 안 되는 최소 운영 체크리스트입니다. 작업 전
- 이 변경이 데이터 변경인지 코드 변경인지 분리했는가?
- 로컬 JSON이 원본으로 남아 있는가?
- 로컬 원천과 DB row가 같은 slug를 가리키는가?
- 되돌리기 방법이 미리 정해져 있는가?
검증 중
- validation이 통과했는가?
- 본문이 독자에게 실제 실행 가치를 주는가?
- 금지어(내부, 임시, TODO 등)가 없는가?
- DB 업로드 대상 post id와 slug가 정확한가?
공개 후
- revalidate 경로에 상세·목록·홈·sitemap이 모두 포함됐는가?
- 라이브 상세와 목록 양쪽에서 새 제목 마커가 보이는가?
- 콘솔 오류가 없는가?
- 공개 알림이 채널로 갔는가?
DB 업로드 후 revalidate 루프의 핵심은 빠른 공개가 아니라 안전한 공개입니다. 코드 배포를 줄이되 검증을 줄이지 않는 것 — 이것이 무배포 포스팅의 성공 조건이고, AI 자동화 시대에 사이트 품질을 지키는 운영 패턴입니다.
자주 묻는 질문
무배포 포스팅의 핵심은 무엇인가요?
코드 배포 없이 데이터 업로드와 revalidate로 공개 화면을 갱신하는 운영 방식입니다. 콘텐츠 수정과 코드 배포를 분리해 작은 변경을 더 빠르고 안전하게 공개할 수 있고, 빌드 시간만큼 공개 속도도 빨라집니다. Vercel 빌드 30초~3분이 1~2초로 줄어듭니다.
revalidate와 빌드는 무엇이 다른가요?
빌드는 코드를 다시 컴파일해 새 번들을 만드는 무거운 작업이고, revalidate는 이미 배포된 코드 위에서 '다음 요청 때 데이터를 다시 가져와라'는 신호만 보내는 가벼운 작업입니다. revalidate는 빌드 큐를 차지하지 않고 1~2초 안에 끝납니다.
revalidatePath와 revalidateTag 중 무엇을 써야 하나요?
둘 다 같이 쓰는 것을 권장합니다. revalidatePath는 특정 경로 하나를 정밀하게 갱신하고, revalidateTag는 같은 태그를 공유하는 모든 캐시를 광역으로 갱신합니다. 보통 상세 페이지는 revalidatePath, 목록·홈·sitemap은 revalidateTag로 처리합니다.
자동 크론과 함께 써도 되나요?
git push를 금지하고 DB 업로드와 revalidate만 수행하도록 권한을 제한하면 안전하게 운영할 수 있습니다. 단, 크론이 만든 글은 status=draft로 먼저 올리고 사람이 published로 바꾸는 흐름을 권장합니다. AI는 초안까지, 사람은 발행 결정까지가 안전한 경계입니다.
로컬 JSON은 왜 유지하나요?
검수 가능한 원천 기록과 되돌리기 기준이 있어야 같은 내용을 다시 배포하거나 이전 버전으로 복구할 수 있기 때문입니다. DB만 보고 작업하면 되돌릴 기준점이 사라집니다. 가능하면 content/ 폴더를 Git으로 관리해 글의 변경 이력을 남기세요. 코드는 배포하지 않더라도 콘텐츠는 버전 관리되어야 합니다.
공개 후 문제가 발견되면 어떻게 되돌리나요?
가장 빠른 방법은 해당 row의 status를 draft로 바꾸거나 publishedAt을 null로 변경한 뒤 revalidate를 다시 호출하는 것입니다. 30초 안에 사이트에서 사라집니다. 전체 복구는 로컬 JSON 이전 버전을 다시 업로드하면 됩니다. 어떤 방법을 쓰든 되돌리기 후에도 live smoke로 공개 화면을 한 번 더 확인해야 합니다.
revalidate가 됐는데도 화면이 안 바뀝니다. 왜 그런가요?
대부분 CDN 캐시 때문입니다. Cloudflare나 다른 CDN이 Next.js 앞단에 있으면 Next.js 캐시는 풀렸어도 CDN이 예전 응답을 들고 있을 수 있습니다. CDN 콘솔에서 해당 경로를 purge하거나, Cache-Control 헤더를 짧게 설정하거나, 캐시 키에 revalidatedAt 타임스탬프를 포함시키는 방법으로 해결합니다.
revalidate API의 보안은 어떻게 챙기나요?
최소 네 가지를 챙기세요. x-revalidate-auth 헤더로 인증, publish 스크립트는 사람 승인 뒤 실행, DB write 토큰과 read 토큰 분리, AI 에이전트의 작업 폴더를 content/로 제한. 인증 없이 revalidate API를 열어 두면 누구나 캐시를 깰 수 있어 DoS 벡터가 됩니다.
이 팁은 어떤 상황에서 가장 효과적인가요?
AI가 콘텐츠를 빠르게 만들지만 배포, 검증, 문서화, 되돌리기 기준이 흐려지는 상황에서 효과적입니다. 작업을 작은 루프로 쪼개고 각 루프마다 확인 가능한 결과를 남기는 데 초점을 둡니다. 특히 뉴스·블로그·튜토리얼처럼 콘텐츠 수정이 잦은 사이트에서 효과가 큽니다.
초보자가 가장 먼저 따라 할 단계는 무엇인가요?
한 번에 큰 기능을 맡기지 말고 작은 변경 하나, 검증 명령 하나, 공개 확인 하나로 루프를 만드세요. 먼저 revalidate API 라우트 하나만 만들고, 손으로 직접 호출해 화면이 갱신되는 것을 확인한 뒤, 그 다음에 자동화 스크립트를 붙이는 순서가 가장 안전합니다. AI에게는 작업 범위와 완료 조건을 명확히 주고, 결과는 사람이 라이브 상세와 목록 양쪽에서 직접 확인해야 합니다.
다음 학습
같은 섹션에서 이어 읽기 좋은 콘텐츠
롤백 가능한 AI 리팩터링
AI 에이전트에게 리팩터링을 맡길 때 가장 위험한 것은 모델이 코드를 못 쓰는 상황이 아닙니다. 큰 diff를 한 번에 만들고, 그 diff가 왜 안전한지 증명하지 못하는 상황이 더 위험합니다. 코드가 그럴듯해 보여도 사용자 동작이 바뀌었는지, API 응답이 깨졌는지, 사이드 이펙트가 생겼는지 확인하지 않으면 리팩터링은 개선이 아니라 장애가 됩니다.
이 글의 결론은 간단합니다. AI 리팩터링은 작게 나누고, 테스트로 고정하고, 언제든 되돌릴 수 있게 끝내야 합니다. AI에게 "이 파일 정리해줘"라고 맡기는 대신, 어떤 동작은 보존해야 하는지, 어떤 파일은 건드리지 말아야 하는지, 어떤 검증을 통과해야 완료인지 먼저 적어야 합니다.
핵심 결론 먼저
AI 코딩은 테스트부터
AI 코딩에서 가장 위험한 순간은 코드가 빨리 나오는 순간입니다. 모델이 빠르게 코드를 내놓으면 사람은 "일단 된 것 같다"고 느끼기 쉽습니다. 하지만 테스트가 없으면 그 코드는 동작하는 코드가 아니라 동작한다고 믿고 싶은 코드입니다.
이 글의 결론은 단순합니다. AI에게 구현을 맡기기 전에 실패를 먼저 재현해야 합니다. 실패 테스트가 있어야 AI가 어디까지 고쳐야 하는지 알 수 있고, 사람이 결과를 감이 아니라 증거로 판단할 수 있습니다.